LAST: Let’s Adapt to System Drift
Project Idea Description
- Topics: Computer systems, machine learning
- Skills: Python, PyTorch, Bash scripting, Linux, Data Science and Machine Learning
- Difficulty: Hard
- Size: Large (350 hours)
- Mentors: Ray Andrew Sinurat (primary contact), Sandeep Madireddy
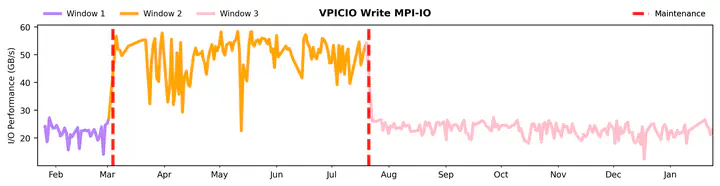
The performance of computer systems is constantly evolving, a natural outcome of updating hardware, improving software, and encountering hardware quirks over time. At the same time, machine learning (ML) models are becoming increasingly popular. They are being used widely to address various challenges in computer systems, notably in speeding up decision-making. This speed is vital for a quick and flexible response, essential for meeting service-level agreements (SLAs). Yet, an interesting twist has emerged: like the computer systems they aid, ML models also experience a kind of “aging.” This results in a gradual decline in their effectiveness, a consequence of changes in their operating environment.
The phenomenon of model “aging” is a ubiquitous occurrence across various domains, not limited merely to computer systems. This process of aging can significantly impact the performance of a model, emphasizing the critical importance of early detection mechanisms to maintain optimal functionality. In light of this, numerous strategies have been formulated to mitigate the aging of models. However, the generalizability and effectiveness of these strategies across diverse domains, particularly in computer systems, remain largely unexplored. This research aims to bridge this gap by designing and implementing a comprehensive data analysis pipeline. The primary objective is to evaluate the efficacy of various strategies through a comparative analysis, focusing on their performance in detecting and addressing model aging. To achieve a better understanding of this issue, the research will address the following pivotal questions:
- Data-Induced Model Aging: What specific variations within the data can precipitate the aging of a model? Understanding the nature and characteristics of data changes that lead to model deterioration is crucial for developing effective prevention and mitigation strategies.
- Efficacy of Aging Detection Algorithms: How proficient are the current algorithms in identifying the signs of model aging? Assessing the accuracy and reliability of these algorithms will provide insights into their practical utility in real-world scenarios.
- Failure Points in Detection: In what scenarios or under what data conditions do the aging detection mechanisms fail? Identifying the limitations and vulnerabilities of these algorithms is vital for refining their robustness and ensuring comprehensive coverage.
- Scalability and Responsiveness: How do these algorithms perform in terms of robustness and speed, particularly when subjected to larger datasets? Evaluating the scalability and responsiveness of the algorithms will determine their feasibility and effectiveness in handling extensive and complex datasets, a common characteristic in computer systems.
To better understand and prevent issues related to model performance, our approach involves analyzing various datasets, both system and non-system, that have shown notable changes over time. We aim to apply machine learning (ML) models to these datasets to assess the effects of these changes on model performance. Our goal is to leverage more advanced ML techniques to create new algorithms that address these challenges effectively. This effort is expected to contribute significantly to the community, enhancing the detection of model aging and improving model performance in computer systems.
Project Deliverable
- Run pipeline on several computer systems and non-computer systems dataset
- A Trovi artifact for data preprocessing and model training shared on Chameleon Cloud
- A GitHub repository containing the pipeline source code
Ray Andrew Sinurat
PhD Student, University of Chicago
Ray Andrew Sinurat is a PhD student at the Department of Computer Science at the University of Chicago
Sandeep Madireddy
Computer Scientist at Argonne National Laboratory
Sandeep Madireddy is a Computer Scientist in the Mathematics and Computer Science Division at Argonne National Laboratory